
Computing capacity is an integral part of climate research. Running large complex climate models and processing large amounts of data require lots of computing capacity. This computer capacity is almost always made available as clusters of lots of specialised high-performance compute servers. Each server has a number of processing units (CPUs) and each CPU usually also has a number of compute cores. The CSAG compute cluster is tiny compared to the systems used to run big global climate model experiments. With just 31 compute servers providing 656 compute cores in our little cluster we are nowhere near making the list of the Top 500 compute clusters in the world! The largest cluster in South Africa is the Lengau system at the Centre for High Performance Computing. This ranks 121st in the Top 500 list and has 24192 compute cores.

Still, with the supporting infrastructure for data storage, web services and other data management tasks this means our little data centre has a power demand of a little under 15kW. It gets worse because essentially what computers do, besides computing, is turn electricity into heat. 15kW is the same as about 7 ovens running flat out so that’s quite a lot of heat and it has to be moved out of that little room. Effectively each watt of compute power needs at least another watt of cooling power for the air-conditioning!
30kW doesn’t sound like that much. Or, does it? 7 ovens, or 15 kettles boiling away 24 hours a day?
A household in Cape Town, just scraping into the Block 1 tariff, will spend about R1200 a month on electricity equating to about 600kWh per month or 20kWh per day. The carbon equivalent for South African electricity seems to be about 0.96kg CO2e per kWh. There are arguments about exactly what it should be and how it is calculated that are summarised in a report by Spalding-Fecher in the Journal of Energy in South Africa. For this discussion let us simply stick with 0.96!
If we do so then our Block 1 household churns out 19.2kg COe per day or 7 tons a year. If you could fly on kg COe this – according to CarbonFootprint.com – would take you to Frankfurt and back 2.69 times in that year.
How does our little data centre stack up?

First we need to go from kW to kWh. kW is a measure of power i.e. the rate at which a system is doing work. The amount of electrical energy consumed over a period is expressed in kWh and this is the ‘unit’ that appears on an electricity bill. So, running at a total power consumption of 30kW the data centre would use 720kWh per day!
Ouch!
Frankfurt and back every 3.76 days.
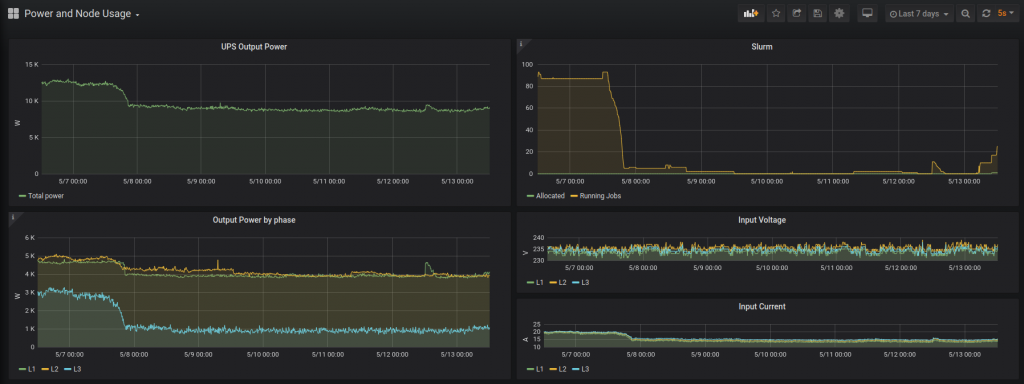
That is probably an over-estimate as cooling demands and efficiency do fluctuate through the year and (as we’ll see below) we aren’t always running at 100% capacity. But it is still a concerning figure!
It is thus essential to make sure that we do two things:
1. Reduce the overall consumption by trying to manage what equipment is used and how it is configured.
2. As far as possible make sure that we only spend kWh on actual useful work. Even when a computer is doing no useful work it is using energy. We can either switch it off completely, or we can make sure that computers that are running are doing something useful.
Option 1 is not always that easy to tackle. Often there are constraints that impact spending decisions: compatibility with existing legacy equipment rather than an open and clean slate approach; institutional constraints on major facilities spending such as aircon units; limited budget limiting how much and what can be done at a particular time… But, within this we have been making inroads to reduce overall consumption by reducing the total number of systems in use.
Option 2 is an area we can and are doing things. Virtualisation, the ability to configure multiple “virtual” servers, many of which can run simultaneously on a single physical server, has been an important part of this. Many servers we run, like mail servers and web servers, don’t actually require that much computing power all the time. Virtualisation allows us to have fewer physical machines and to better utilise the ones we do have.
The second important step is to be able to better manage and monitor power usage. A strategic drive during the course of the last year has been to rework the data centre power reticulation – the network of cables that supplies the power to the computers. Previously the power came to the facility by diverse and mysterious cables connected to a variety of distribution boards in the building. It now comes in via a single cable to a consolidated distribution board in the data centre. From here it runs into a large new Uninterruptible Power Supply (UPS) and then on to the computers themselves. The UPS is essentially just a big battery which can run the whole compute center for a few minutes between when Eskom power goes down and the diesel generator outside (hopefully) starts up and takes over.
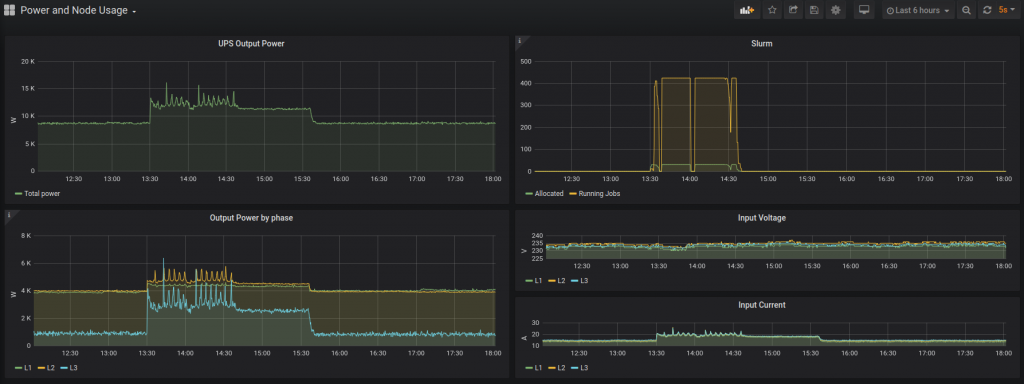
A key extra feature of the UPS is that it enables the power usage to be measured and this is helping to ensure that kWh are meaningfully used.
To use the compute cluster you need to tell it to run your code by submitting a compute “job”. This is so that the cluster can fairly share out jobs from lots of users across the compute nodes. Job submission to the compute nodes is now managed by the Slurm job scheduler. This has been another strategic drive over the course of the last year that is now helping to manage power consumption! We have setup Slurm to power down nodes that are not actively being used for running jobs. It does this by a normal OS shutdown command to switch the nodes off. That’s the easy part. But what if we need more compute power again? How do you turn on a computer that is off if you can’t push the on button? Well luckily computer people have never really liked having to stand up and walk so that many years ago this problem was solved. Laziness is a source of a great deal of inventiveness! The solution is just to configure an IPMI host to issue IMPI commands to the nodes BMC… And you thought CMIP5, ECMWF and SNOTS where useful acronyms!
The real trick is that even when a computer server is turned off, its not really off. There is a little “computer” call the Baseboard Management Controller (BMC) that stays powered on and just sits listening for instructions. It can execute commands, like powering on the full server. Instructions come from an Intelligent Platform Management Interface (IPMI) server and IPMI is a protocol for talking to the BMC.
When Slurm receives a request for a job resource, if no available running nodes can meet the request, it contacts the management host and asks for a node to be turned on. The management host issues the appropriate IPMI command to power up a compute node. The BMC receives this command and is able to power up the full compute node, just as if someone had pushed the power button. Once the scheduler can see the compute node is running and ready to execute jobs, the job is submitted in the normal way. This does mean that the first job submission request for a resource will take longer – usually about 2 minutes. Subsequent requests will happen quickly. If no resource is requested within a certain period – for now 1 hour – Slurm will start shutting down nodes until the required idle state is reached.
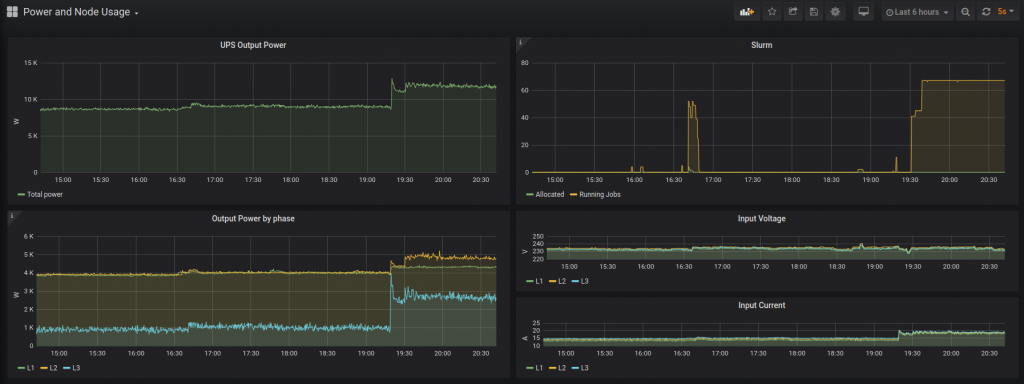
This results in a difference of 3kW to 4kW [direct load] between idle and fully operational. Including reduced cooling need this is a saving of between 6kW and 8kW.
22.64 [exactly] fewer flights to Frankfurt every year!
Next steps will be harder to achieve. Our legacy storage system does not offer any interface for power management and it probably consumes about 60% of the remaining power. We’ve been moving over to a new distributed storage platform using the Beegfs file system. This setup uses drives that are physically located on machines running CentOS and so can be managed by the OS power management interface. Of course shutting down storage servers that aren’t being used isn’t that practical. Besides an order of magnitude more technical complexity, not many of you would be happy to wait 2-3 minutes for a server to power up so that you can open a file!
It is worth noting though that if we calculate power usage per terrabyte (TB) of storage provided, the numbers are continually improving because we are packing more and more TB into each hard disk and each storage server while power usage isn’t really increasing proportionally.
Of course, the other side of this whole story is where our electricity comes from. Perhaps in another post we can map out what it would take to be the first solar powered climate compute center in Africa…
Thank-you to Chris Jack and Phillip Mukwena for ongoing contributions to this work.